While Ada Lovelace lives on as an inspiration to women working and researching in STEM subjects through the activities of Ada Lovelace Day, her impact can also be seen in the literature. Using tools available from Digital Science, Simon Linacre looks at the ever-increasing amount of research surrounding one of science’s most fascinating figures.
Firstly, a confession: before starting work for Digital Science in early 2022, I didn’t know who Ada Lovelace was. I knew the name, and may have known she had been a scientist of some description, but I had no idea what she had achieved or when she had achieved it. Put it down to my preference for the arts in my education, a patriarchal society or just sheer ignorance, but I had no idea what an inspirational figure she was. Of course, now I know a lot more having worked with Digital Science in its support of Ada Lovelace Day, but I wanted to know more. As someone who has worked in scholarly communications for most of their career, what does her legacy look like in the current literature?
At first glance, it is pretty significant. According to the Dimensions linked database – which covers 131 million publications – there are over 15,000 mentions of ‘Ada Lovelace’ in those publications, as well as 74 policy documents and 29 patents. There are even mentions in eight grant applications. Looking at who is doing the mentioning, it includes some major institutions in scientific research, including Oxford, Cambridge and University College London.
Having said that, most publications originated in the US and not the UK, which shows that her influence has not been limited to her country of birth.
This wider influence is also in evidence when it comes to research categories. While it is unsurprising that the most common research category with mentions of her name is Information and Computing Sciences (716 mentions), not far behind are Philosophy and Religious Studies (486), Language, Communication and Culture (271) and Human Society (240). Lovelace has clearly had quite a broad spectrum of influence, far outside of her ‘home’ of computing sciences.
And the influence appears to be growing. As you can see from the chart, despite a lull around 2018, interest in Ada Lovelace has been growing steadily in recent years, with some acceleration more recently when we look at total outputs of publications that mention her name.
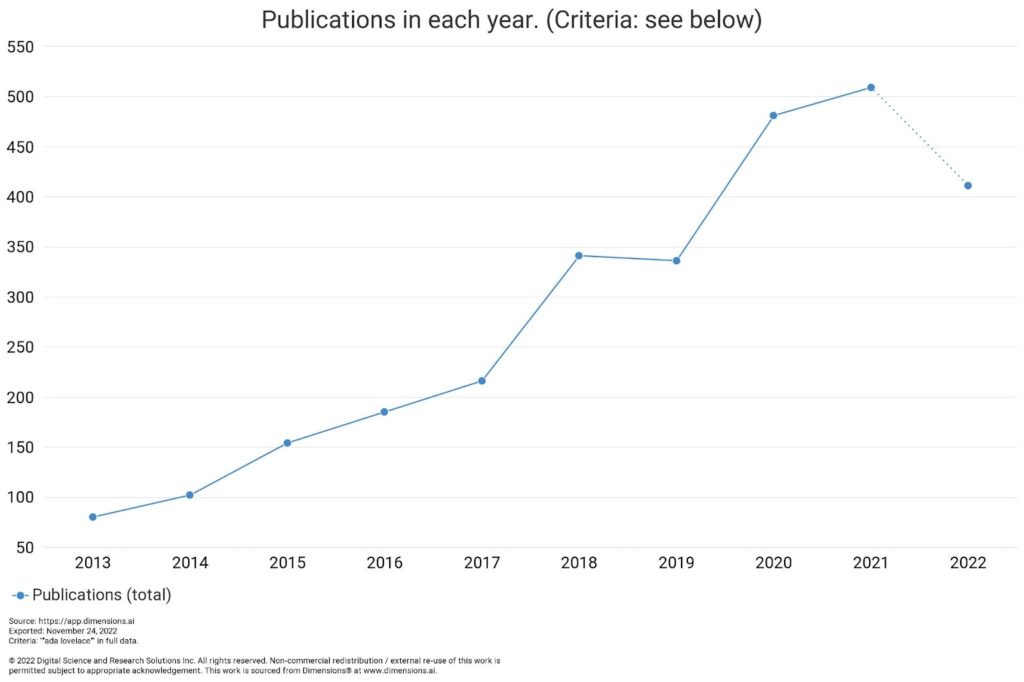
Perhaps one reason for her popularity is the proportion of articles that mention her being open access, with 79% of them being free to read online.
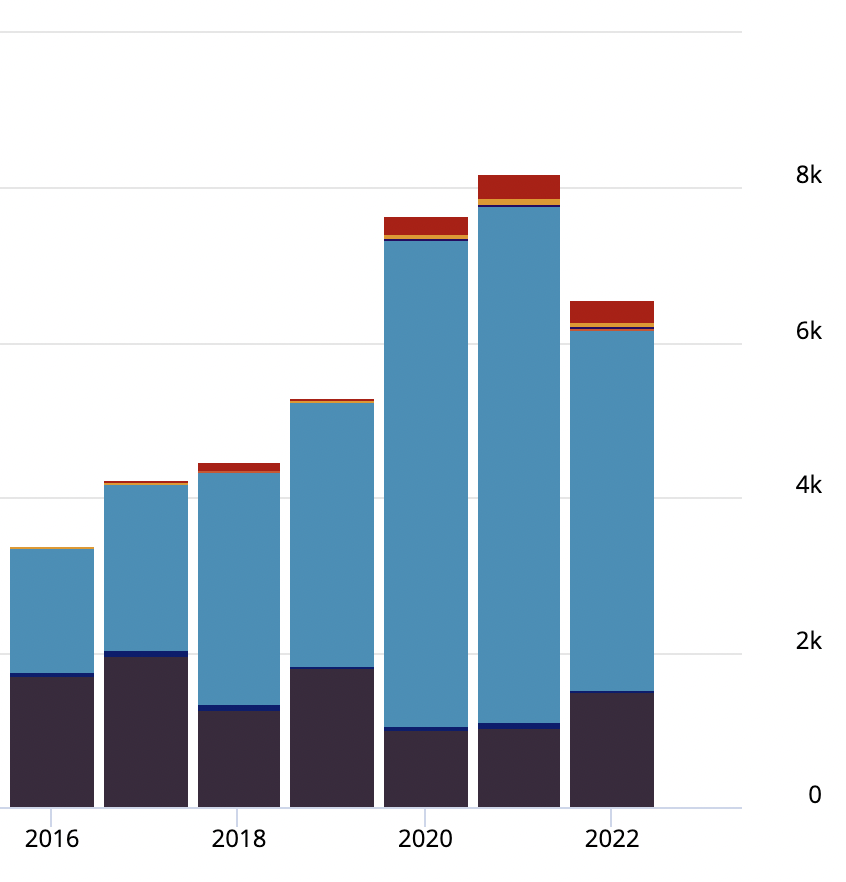
Focusing again on the present day, Ada Lovelace has also made somewhat of a splash online. When we look at Altmetric data, we see that the increase in mentions trackable on the internet have also seen rapid growth since 2016, the year after her bicentenary, and especially in the last couple of years. In 2021 alone (see below) there were over 8,000 recorded instances, including 6,662 Twitter mentions, 1,028 Wikipedia mentions and 312 news items.
So, who was Ada Lovelace? These days, she is best known for being the first person to publish what would today be called a computer program.
Throughout her childhood she was fascinated by machines, and at the age of 17, she was introduced to the engineer and inventor, Charles Babbage, and his general purpose mechanical computer, the Analytical Engine. Lovelace and Babbage became life-long friends, and Lovelace came to understand the Analytical Engine in depth.
When Italian mathematician Luigi Menabrea published an article about the Analytical Engine in French, she translated it into English, correcting some errors as she went. Babbage suggested that she added her own footnotes, which she did, tripling the length of the paper.
In these footnotes, Lovelace wrote a set of instructions for the calculation of Bernoulli Numbers. Although Babbage had written fragments before, her more elaborate program was complete and the first to be published. She also speculated on the future capabilities of the Analytical Engine, suggesting that it could be used to create original pieces of music and works of art, if only she knew how to program it. She recognised the enormous potential of machines like the Analytical Engine and her vision bears a striking resemblance to modern computer science.
Lovelace’s work was truly ground-breaking and her achievements become even more impressive when one remembers that she was working from first principles with only Babbage’s designs and descriptions to guide her and no working computer to tinker with. Yet, the importance of her paper was not recognised until Alan Turing’s work on the first modern computers in the 1940s.
As we can see from the data, Lovelace is now a widely cited and mentioned mathematician who is increasingly influencing a broad range of STEM and social science areas. Not only does the legacy of Ada Lovelace live on, it has never been bigger or more important.
About Digital Science
 Digital Science is a technology company serving the needs of scientific research. We offer a range of scientific technology and content solutions that help make scientific research more efficient. Whether at the bench or in a research setting, our aim is to help to simplify workflows and change the way science is done. We believe passionately that tomorrow’s research will be different – and better – than today’s. Follow Digital Science on Twitter: @digitalsci
Digital Science is a technology company serving the needs of scientific research. We offer a range of scientific technology and content solutions that help make scientific research more efficient. Whether at the bench or in a research setting, our aim is to help to simplify workflows and change the way science is done. We believe passionately that tomorrow’s research will be different – and better – than today’s. Follow Digital Science on Twitter: @digitalsci
 Thanks to generous support from The Royal Institution, Stylist, Redgate, The Information Lab’s Data School and dxw, Ada Lovelace Day Live 2023 will now go ahead on the evening of Tuesday 10 October.
Thanks to generous support from The Royal Institution, Stylist, Redgate, The Information Lab’s Data School and dxw, Ada Lovelace Day Live 2023 will now go ahead on the evening of Tuesday 10 October.
 By Rebecca Whitworth, Manager, Software Engineering at Red Hat.
By Rebecca Whitworth, Manager, Software Engineering at Red Hat. 